728x90
3.1 데이터 분석에서 중요한 넘파이
빅데이터의 분석의 대상이 되는 데이터는 한 두개 정도의 간단한 수치 데이터가 아니라 많은 양의 연속적인 데이터가 많다. 이러한 연속적인 데이터를 다룰 수 있는 파이썬의 대표적인 자료구조는 리스트(list)
다만, 대규모 수치 데이터를 다루는 과학 분야에서 파이썬의 리스트는 성능 측면에서 만족스럽지 못한 경우가 많다. 이 때문에 과학기술 분야에서 수치를 다룰 때는 파이썬의 리스트 보다는 넘파이(numpy)에서 제공하는 다차원 배열을 선호
넘파이의 주요 특징들
- 고성능 다차원 배열 객체를 제공
- 빠른 배열 연산
- 백터화와 브로드캐스팅 기능
- 다양하고 강력한 수학 함수
- C, C++ 포트란 코드와의 통합
- 기계학습 라이브러리의 기반
- C/C++, 자바와 같은 많은 프로그래밍 언어에서의 배열은 동일한 자료형을 가진 데이터를 연속으로 저장
- 넘파이의 ndarray 객체는 C/C++, 자바와 유사하게 동일한 자료형을 가진 데이터만 저장
- 넘파이가 원소에 접근하는 속도가 더 빠름
- 리스트는 데이터를 벡터의 개념으로 해석하지 않고, 단순히 여러 데이터가 나열된 것으로만 생각하지만, 넘파이는 배열을 선형대수의 벡터 개념으로 다룸
- 같은 인덱스를 가진 원소들끼리 더해야 의미있는 값을 얻을 수 있음
- 넘파이는 대응되는 인덱스들이 더해지고 뺄 수 있는 연관된 데이터라고 가정
- 즉, 데이터를 벡터로 간주하는 것
3.2 넘파이의 별칭 만들기, 그리고 간단한 배열 연산하기
import numpy as np
store_a = [20, 10, 30]
store_b = [70, 90, 70]
# store_a 리스트와 store_b 리스트를 넘파이 배열로 변환
np_store_a = np.array(store_a)
np_store_b = np.array(store_b)
# 넘파이 배열은 인덱스별로 더하고 뺄 수 있음
array_sum = np_store_a + np_store_b
array_sum
# 출력 결과
# array([90, 100, 100])- 넘파이의 핵심적인 객체는 다차원 배열
- 다차원 배열의 내용물을 성분 또는 요소, 항목이라고 하며, 각 요소는 인덱스라고 불리는 정수를 사용하여 참조 가능
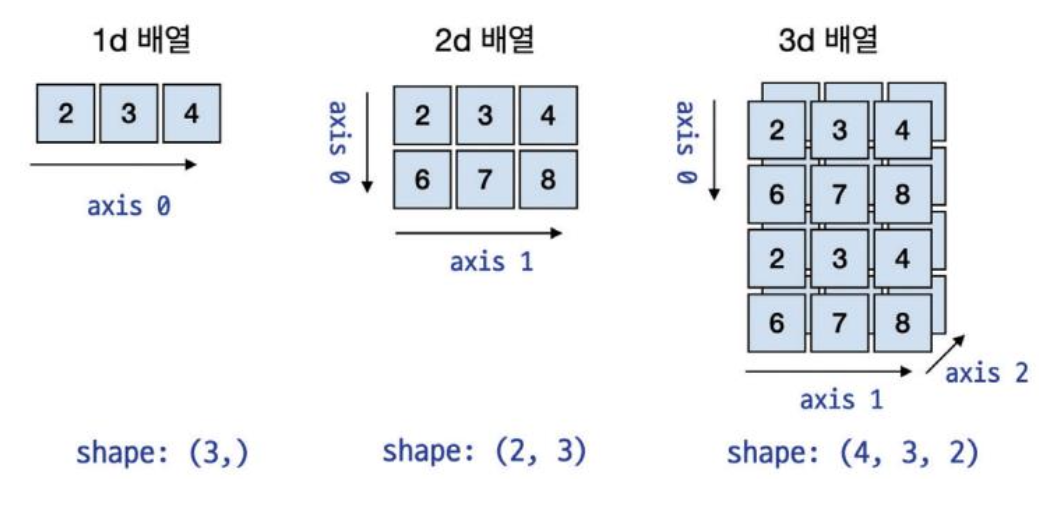
- 넘파이에서 차원은 축(axis)이라고 불리며, 그림은 1차원 2차원 3차원 배열과 그 축을 나타내고 있음
- 다차원 배열은 형상(shape)으로 전체적인 모양 나타낼 수 있음
- 형상은 다차원 배열의 shape라는 속성으로 출력할 수 있음
ndarray
- 넘파이는 성능이 우수한 다차원 배열 객체를 제공한다. 이 다차원 배열 객체를 ndarray라고 한다.
ndarray의 장점
- ndarray는 C 언어에 기반한 배열 구조이므로 메모리를 적게 차지하고 속도가 빠르다
- ndarray를 사용하면 배열과 배열 간에 수학적인 벡터 연산을 이용할 수 있다
- ndarray는 고급 연산자와 풍부한 함수들을 제공한다

3.3 강력한 넘파이 배열 연산을 알아보자
shape
- 다차원 배열의 행과 열을 비롯한 차원의 형상을 출력하는 shape 속성은 넘파이 이용자들이 가장 자주 사용하는 속성
import numpy as np
b = np.array([[1,2,3],[4,5,6]])
b.shape
# (2, 3)- 다차원 배열은 파이썬 리스트와 유사하게 +나 * 연산자 적용 가능
넘파이 배열의 데이터 타입을 지정하는 방법
- 프로그래밍 언어에서 자료형이란 데이터의 자료값이 정수인지, 실수인지, 문자인지 그 종류를 나타내는 개념
import numpy as np
# dtype = np.int32와 같이 int32 속성값으로 지정하기
a = np.array([1,2,3,4], dtype = np.int32)
# dtype = 'int32'와 같이 문자열 형식으로 속성값 지정하기
a = np.array([1,2,3,4], dtype = 'int32')
import numpy as np
salary = np.array([200, 210, 240, 310])
salary = salary + 50
print(salary)
# [250 260 290 360]- 넘파이 배열에 저장된 모든 값에 50씩 더하려면 단순히 배열에 스칼라 값 50을 더하면 됨
- 곱셈 연산은 2.2와 같이 실수 값을 적용할 수도 있음
import numpy as np
array_a = np.array([0,1,2,3,4,5,6,7,8,9])
array_b = np.array(range(10))
array_c = np.array(range(0,10,1))3.4 넘파이 배열 계산은 왜 빠른가
파이썬의 리스트는 다양한 자료형의 값을 가질 수 있다. 반면, 넘파이 배열 안에는 동일한 타입의 데이터만 저장할 수 있음.
만약 여러가지 타입을 섞어서 넘파이의 배열에 전달하면 넘파이는 이걸 전부 문자열로 변경
동일한 자료형으로만 데이터를 저장하면 각각의 데이터 항목에 필요한 저장 공간이 일정하다.
따라서 몇 번째 위치에 있는 항목이든 그 순서만 안다면 바로 접근할 수 있기 때문에 빠르게 데이터를 다룰 수 있다.
임의 접근: 넘파이의 다차원 배열은 인덱스를 통해 원하는 위치의 데이터에 바로 접근하여 데이터를 읽고 쓰는 일을 할 수 있다.

편리하고 강력한 브로드캐스팅과 벡터화 연산
- 브로드캐스팅: 넘파이에서 다차원 배열과 스칼라의 덧셈이나 뺄셈 연산을 수행하려면 두 데이터의 차원이 일치해야 한다. 이 때, 스칼라 값을 다차원 배열과 같이 벡터로 확장시켜주는 작업을 브로드캐스팅이라고 한다.
- 벡터화 연산: 넘파이에서 하나의 명령을 여러 데이터에 적용하여 병렬적으로 연산하는 것

3.6 인덱싱과 슬라이싱을 넘파이에서도 할 수 있다
- 넘파이 배열에서 특정한 요소를 추출하려면 인덱스를 사용
- 넘파이 배열에서 특정한 요소의 집합을 얻기 위해서는 슬라이싱을 사용
- 시작 인덱스나 종료 인덱스는 생략 가능
- scores[2:-1]과 같은 음수 인덱싱도 가능
scores = [1, 2, 3, 4, 5]
scores[:3] # array([1, 2, 3])
scores[3:] # array([4, 5])
scores[2:-1] # array([3, 4])부울 인덱싱
- 부울 인덱싱이란 넘파이의 배열에 특정한 조건을 주고, 이 조건을 통해서 원하는 값을 추려내는 기법
import numpy as np
scores = np.array([10, 20, 30, 40, 50])
passed = scores >= 30
passed
# array([False, False, True, True, True])# 배열 요소들 중에서 30점 이상인 값들만 뽑아내기 위해서는 scores[조건식]사용
scores[passed]
# array([30, 40, 50])3.7 2차원 배열의 인덱싱
- 넘파이 다차원 배열은 데이터가 구성되는 축의 수에 따라 1차원, 2차원 ... 배열로 나누어 볼 수 있다.
- 파이썬의 이차원 리스트는 "리스트의 리스트"
3.8 2차원 배열 슬라이싱하기
넘파이는 넘파이 스타일로 인덱싱할 수 있다

import numpy as np
np_a = np.array([[1,2,3,4],
[5,6,7,8],
[9,10,11,12],
[13,14,15,16]])
np_a[::2][::2]
# array([1, 2, 3, 4])
np_a[::2, ::2]
# array([[ 1, 3], [ 9, 11]])- np_a[::2][::2]는 슬라이싱 결과에 대해 또 슬라이싱하는 것이고,
- np_a[::2, ::2]는 한 번에 행과 열을 동시에 슬라이싱하는 것이다.
2차원 배열의 논리 인덱싱
np_array([[1,2,3],[4,5,6],[7,8,9]])
# np_array 배열 내에서 6보다 큰 값만 뽑아내려면
np_array[ np_array > 6 ]
# array([7, 8, 9])
# 세 번째 열을 추려내는 연산
np_array([3, 6, 9])
# 슬라이싱의 결과 값 [3, 6, 9] 중에서 5를 넘는 값이 있는지를 부울형으로 반환
np_array[:, 2] > 5- 넘파이의 텐서는 3차원 배열뿐만 아니라 모든 차원의 배열을 포괄하는 개념이므로
- 벡터는 1차원 텐서, 행렬은 2차원 텐서라고 할 수 있다.
3.9 arrange()함수와 range() 함수의 비교
import numpy as np
np.arange(4)
# arrange([0, 1, 2, 3])
np.arange(1, 4)
# arrange([1, 2, 3])
np.arange(1, 4, 2)
# arrange([1, 3])
np.arange(1, 10, 2.5)
# arrange([1., 3.5, 6., 8.5])- numpy의 arange는 실수값 step이 가능 (파이썬 range와의 차이점 - arange는 실수값 step이 가능)
3.10 linspace()함수와 logspace() 함수
linspace()는 특정한 구간의 값을 주어진 수만큼 균등하게 나누어 그 값들을 반환하는 함수
import numpy as np
np.linspace(start, stop, num=50)
np.linespace(0, 10, 11)
# array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.])- 시작값(start) 부터 마지막 값(stop)까지 균일한 간격으로 지정된 수(num) 만큼의 배열을 생성
- 데이터 생성 개수는 기본값이 50개이다.
logspace()는 로그 스케일로 수들을 생성
import numpy as np
np.logspace(0, 5, 6)
# array([1.e+00, 1.e+01, 1.e+02, 1.e+03, 1.e+04, 1.e+05])배열의 형태를 바꾸는 reshape()와 flatten() 명령
reshape()는 데이터의 개수는 유지한 채로 배열의 차원과 형태를 변경
import numpy as np
a = np.arange(10)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
a.reshape(2, 5)
a.reshape(-1, 5)
# array([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]])
flatten()은 다차원 배열을 1차원 배열로 만들어줌
a.flatten()
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])3.11 다차원 배열을 결합하자
concatenate(), vstack()
np.concatenate((a, b)) # 이중괄호 필수
np.vstack((a, b))
hstack()
axis 0의 차원값이 동일한 때에만 두 벡터를 수평축으로 결합
np.hstack((a, c))
3.12 다차원 배열을 결합하는 다양한 방법
import numpy as np
a = np.array([1, 2, 3])
b = np.array([10, 20, 30])
c = np.array([[1, 2, 3], [4, 5, 6]])
d = np.array([[10, 20, 30], [40, 50, 60]])

전치행렬
- 행렬의 행과 열을 뒤집은 행렬을 전치행렬이라고 한다.
c = [[1, 2, 3], [4, 5, 6]]
# c의 전치 행렬
c.T = [[1, 4], [2, 5], [3, 6]]3.13 다차원 배열의 축과 원소의 삽입
insert()
- insert()함수는 np.insert(배열 객체, 삽입할 위치, 삽입할 값, 삽입 방향)
b = np.array([[1,1],[2,2],[3,3]])
np.insert(b, 1, 4, axis=0)
np.insert(b, 1, [4,4], axis=0)
# array([[1,1],[4,4],[2,2],[3,3]])b = np.array([[1,1],[2,2],[3,3]])
np.insert(b, 1, 4, axis=1)
# array([[1, 4, 1],[2, 4, 2],[3, 4, 3]])flip()
- 지정된 축방향으로 원소들을 뒤집어 줄 수 있음
c = np.array([[1,2,3],[4,5,6]])
np.flip(c, axis=1)
# array([[3,2,1],[6,5,4]])
np.flip(c, axis=0)
# array([[4,5,6],[1,2,3]])728x90
'Data > Bigdata' 카테고리의 다른 글
| [Bigdata] 5. 맷플롯립 알아보기 (0) | 2025.04.28 |
|---|---|
| [Bigdata] 4. 넘파이의 세계로 (0) | 2025.04.28 |
| [Bigdata] 슬라이싱 정리 (0) | 2025.04.28 |
| [Bigdata] 2. 데이터 분석을 위한 도구 (0) | 2025.04.27 |
| [Bigdata] 1. 빅데이터로 통하는 세상 (0) | 2025.04.27 |