그룹핑이 점점 중요해지고 있음! (⭐️)
1. 그룹핑
groupby를 사용해 기준컬럼대로 그룹핑을 실행
# 원산지 기준, 평균
df.groupby(['원산지']).mean(numeric_only=True)
# 원산지와 칼로리 기준, 평균
df.groupby(['원산지','칼로리']).mean(numeric_only=True)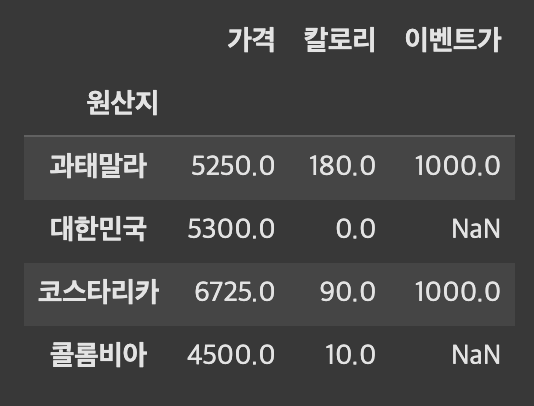

여러 기준컬럼과 여러 값(평균, 합계 등등..)을 그룹핑할 때, 여러 개의 함수를 한번에 적용하고 싶을 땐 agg를 사용
# 원산지와 메뉴 기준 (평균, 합계)
df.groupby(['원산지', '메뉴']).agg(['mean','sum'])
그룹핑된 인덱스에서 개별 인덱스 형태로 리셋할 때는 뒤에 reset_index()만 붙여주면 된다.
# 1개 인덱스 형태로 리셋
df.groupby(['원산지', '메뉴']).mean(numeric_only=True).reset_index()

결측값이 있을 땐, 결측값에 평균/최빈/중앙값을 넣어준다.
transform을 사용해 그룹핑을 실행
import pandas as pd
# 데이터 생성 (일부 결측값 포함)
df = pd.DataFrame({
'과일': ['딸기', '블루베리', '딸기', '블루베리', '딸기', '블루베리', '딸기', '블루베리'],
'가격': [1000, None, 1500, None, 2000, 2500, None, 1800] # 결측값 포함
})
df
이런 형태의 데이터프레임이 있다고 가정했을 때, 블루베리와 딸기 중 NaN(결측값)이 있는 데이터의 경우 다른 값을 넣어줘야 한다. 그러기 위해선 과일별 평균 가격을 먼저 알아야 하는데, 이때 transform을 사용한다.
price = df.groupby('그룹 기준 컬럼명')['계산할 기준 컬럼'].transform('평균/중앙/최빈.. 등등')
# 과일별 평균 가격 구하기
price = df.groupby('과일')['가격'].transform('mean')
price
이후 결측치를 fillna를 사용해 price로 채운다.
df['가격'] = df['가격'].fillna(price)
df
unstack을 사용해 그룹핑 진행
import pandas as pd
coffee_data = {
'커피종류': ['아메리카노', '아메리카노', '아메리카노', '라떼', '라떼', '라떼'],
'컵크기': ['Small', 'Medium', 'Large', 'Small', 'Medium', 'Large'],
'판매량': [120, 150, 200, 100, 130, 180]
}
df = pd.DataFrame(coffee_data)
df
이런 형태의 데이터프레임이 있다고 가정했을 때, groupby를 적용하면 아래와 같은 데이터프레임으로 그룹핑된다.
# groupby 적용
grouped = df.groupby(['커피종류','컵크기'])['판매량'].sum()
grouped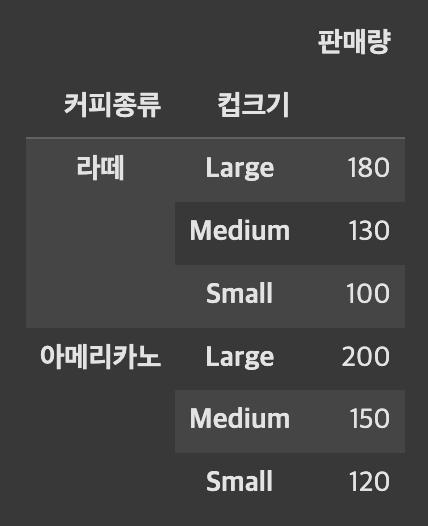
컵크기를 컬럼으로 변환시키기 위해서는 unstack()을 사용하면 된다.
level = -1은 가장 오른쪽에 그룹핑되어있는 컬럼을 말한다. 즉, '컵크기' 안의 Small Medium Large가 컬럼이 된다.
grouped.unstack()
grouped.unstack(level=-1)
만약 커피종류를 컬럼으로 바꾸고 싶다면, unstack 내부에 level=0을 넣어주면 된다.
grouped.unstack(level=0)
grouped.unstack().unstack()
2. 병합
concat은 데이터프레임을 행 또는 열 방향으로 연결한다.
연결하는 데이터프레임의 구조와 인덱스는 유지되며, 연결한 결과는 단순히 데이터프레임을 이어붙인 형태로 반환된다.
일반적으로 pd.concat은 데이터프레임을 단순히 결합하고자 할 때 사용되는데 예를 들어, 여러 개의 데이터프레임을 행 방향으로 연결하여 전체 데이터셋을 구성하는 경우에 사용할 수 있다.
import pandas as pd
# 에피타이저 메뉴
appetizer = pd.DataFrame({
'Menu': ['Salad', 'Soup', 'Bread'],
'Price': [5000, 3000, 2000]
})
# 메인 메뉴
main = pd.DataFrame({
'Menu': ['Steak', 'Pasta', 'Chicken'],
'Price': [15000, 12000, 10000]
})
print(appetizer)
print(main)
에피타이저 메뉴와 메인 메뉴 데이터프레임이 따로 있다고 했을 때, 수직으로 병합하는 방법은 concat과 axis=0을 사용해준다.
axis=0은 기본이기 때문에 기입해주지 않아도 된다.
full_menu = pd.concat([appetizer, main], axis=0)
full_menu아래처럼 병합을 할 경우 인덱스가 섞여서 병합된다.
ignore_index=True 를 넣어 기존 인덱스를 무시하고 새로운 인덱스를 부여하면 된다.
full_menu = pd.concat([appetizer, main], axis=0, ignore_index=True)
full_menu
axis=1을 사용하면 두 데이터 프레임을 좌우로 연결할 수 있다.
full_menu = pd.concat([appetizer, main], axis=1)
full_menu
merge는 두 개 이상의 데이터프레임을 공통된 열 또는 인덱스를 기준으로 병합(merge)한다.
병합 기준으로 사용되는 열 또는 인덱스를 기준으로 데이터프레임을 조인(join)한다고 생각하면 쉽다.
데이터프레임 간에 공통된 열이나 인덱스가 있어야 한다.
# 메뉴와 가격
price = pd.DataFrame({
'Menu': ['Salad', 'Soup', 'Steak', 'Pasta'],
'Price': [5000, 3000, 15000, 12000]
})
# 메뉴와 칼로리
cal = pd.DataFrame({
'Menu': ['Soup', 'Steak', 'Pasta','Salad'],
'Calories': [100, 500, 400, 150]
})price와 cal이라는 두 데이터프레임이 있을 때, Menu를 기준으로 병합하고 싶을 경우 merge를 사용한다.
pd.merge(데이터프레임1, 데이터프레임2, on="기준컬럼")
full_menu = pd.merge(price, cal, on="Menu")
full_menu3. 피벗테이블
import pandas as pd
# 직원별 부서 및 급여 정보
data = {
'이름': ['서아', '다인', '채아', '예담', '종현', '태헌'],
'부서': ['개발', '기획', '개발', '기획', '개발', '기획'],
'급여': [3000, 3200, 3100, 3300, 2900, 3100]
}
df = pd.DataFrame(data)
print("[원본 데이터]")
print(df)
# 부서별 평균 급여 계산
df.pivot_table(index="부서", values="급여", aggfunc="mean")# 부서와 직급별 급여 정보
data = {
'부서': ['개발', '기획', '기획', '기획', '개발', '개발'],
'직급': ['대리', '과장', '대리', '과장', '대리', '과장'],
'급여': [3000, 4000, 3200, 4200, 3500, 4500]
}
df = pd.DataFrame(data)
print("[원본 데이터]")
print(df)
# 부서 및 직급별 급여 합계 계산
df.pivot_table(index='부서', columns='직급', values='급여', aggfunc='sum')pd.pivot_table(df, # 피벗할 데이터프레임
index = '부서', # 행 위치에 들어갈 열
columns = '직급', # 열 위치에 들어갈 열
values = '급여', # 데이터로 사용할 열
aggfunc = 'sum') # 데이터 집계함수pivot_table을 사용하면 데이터프레임 내에서 행 위치에 들어갈 컬럼을 가져오고, 열 위치에 들어갈 컬럼을 가져오고, 데이터에 사용할 컬럼과 집계함수를 설정하여 새로운 데이터프레임을 만든다.
# 다양한 집계를 위한 데이터셋
import pandas as pd
df = pd.DataFrame({
"구분": ["전자", "전자", "전자", "전자", "전자", "가전", "가전", "가전", "가전"],
"유형": ["일반", "일반", "일반", "특수", "특수", "일반", "일반", "특수", "특수"],
"크기": ["소형", "대형", "대형", "소형", "소형", "대형", "소형", "소형", "대형"],
"수량": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"금액": [2, 4, 5, 5, 6, 6, 8, 9, 9]
})
print(df)집계시 NaN으로 되어있는 경우 fill_value를 통해 fillna와 같이 결측치에 지정 값을 넣을 수 있다.
df.pivot_table(index=["구분", "유형"], columns="크기", values="수량", aggfunc="sum")
df.pivot_table(index=["구분", "유형"], columns="크기", values="수량", aggfunc="sum", fill_value=0)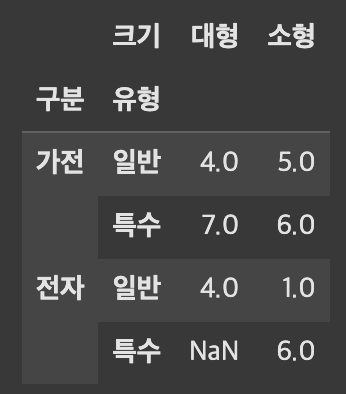

# 여러 열에 대해 각기 다른 집계 함수 적용 (좌)
df.pivot_table(index=["구분", "크기"], values=["수량", "금액"], aggfunc={"수량": "mean", "금액": "mean"})
# 하나의 열에 대해 여러 집계 함수를 동시에 적용 (우)
df.pivot_table(index=["구분", "크기"], values=["수량", "금액"], aggfunc={"수량": "mean", "금액": ["min", "max", "mean"]})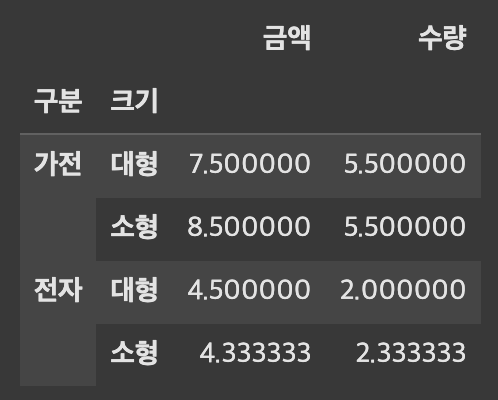

'Data > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사] 판다스7-시계열데이터2 (0) | 2025.06.12 |
|---|---|
| [빅데이터분석기사] 판다스6 - 시계열 데이터1 (0) | 2025.06.11 |
| [빅데이터분석기사] 판다스4 - 문자열, 내장함수 (1) | 2025.06.10 |
| [빅데이터분석기사] 판다스3 - 추가/변경, 정렬, 필터링, 결측치, 값 변경 (0) | 2025.06.09 |
| [빅데이터분석기사] 판다스2 - 자료형, 컬럼, 삭제, 인덱싱/슬라이싱 (0) | 2025.05.28 |